

Event Summary October 12, 2016
Introduction

New York City, New York
The O’Reilly Artificial Intelligence 2016 conference was held September 26 and 27, 2016, at the Javits Center in NYC. The venue was great — a view of the Hudson, with floor-to-ceiling windows, and the High Line (a pedestrian path on the west side of Manhattan) nearby.
The attendees were disproportionately founders, VCs, CEOs and other senior executives, but also included a lot of lead engineer / developer / data scientist positions at companies working in AI. I spoke with a Partner at EY about how they’re looking for new technologies to offer their clients.
Keynote speakers of note were Tim O’Reilly (founder of O’Reilly Media, the organizer of the conference, Peter Norvig (Director of Research at Google, formerly its Director of Search Quality), and Yann Le Cun (Director of AI Research at Facebook, Founding Director of the NYU Center for Data Science, etc.). Other keynote speakers were also heavily credentialed, from companies like Intel, Google and Microsoft; but also included several founders and CEOs of companies with an AI focus, possibly in part because their companies partially funded the conference.
Overview
As you’d expect from an inaugural conference on a topic like Artificial Intelligence, an almost mystical belief in the power of AI and its limitless potential prevailed. For the record, I also often get swept up in its potential (it’s clearly an engineering feat to beat the world’s best Go player, self-driving cars actually exist and are in use, AI software can often read medical images better and certainly faster than humans, etc.) – but mostly when I define AI as most presenters did, to mean a narrower sense of machine intelligence applied to a specific domain. AI right now is a mix of large recent strides, huge potential and irrational exuberance.
Some grand themes emerged over the course of the conference:
- For some kinds of problems, humans just can’t outperform AI, especially those that involve truly large data sets or processing power on a narrow, well-defined domain like chess or Go; but also where humans just aren’t that good, or are wildly inconsistent, like driving.
- A particular class of algorithms collectively called Deep Learning will change the world as we know it. It’s easy to get caught up in this: just look at all of the recent strides. From there, it’s a natural leap to “it’s magic — there’s nothing it can’t do!” (reminiscent of the big data hype of the last few years). However, it’s hard to deny that there have been significant performance improvements and new products leveraging these technologies recently.
- There were several presenters whose main message boiled down to something like “adding humans to the loop in an AI process works better than using either one alone”. This is essentially a recognition that AI is not yet able to replicate human judgment in many situations, for example, selecting good clothing for various events, considering all the nuances of fashion and etiquette. Thus, it’s likely that selected parts of processes will be automated, and humans will need to adapt to working alongside smart machines (just as we’ve done many times before, including widespread use of computers themselves).
Reality Check
In the excitement and rampant optimism in evidence, sometimes a splash of cold water is called for: AI mostly works on the normal cases of well-defined domain problems; it still fails on the long tail “edge cases”. Much of what people are calling “AI” is really machine learning applied to a narrow, controlled domain. General (strong) AI is defined as truly human-like behavior, and under this definition, AI is significantly less accomplished than almost every grade-schooler.
The reality is that AI is still quite immature, especially in tooling around development of neural networks and other kinds of models that are fairly opaque. It doesn’t do well with “edge cases” that happen daily in large populations. No one thinks the world is ready for truly driverless cars at scale, despite billions of dollars of research over many years.
Session Highlights
Some highlights of the sessions I attended follow:
Peter Norvig
- “AI is a black box with the covers opened” (so you can peek in a little).
- Machine Learning (a concept almost indistinguishable from AI) is “The High-Interest Credit Card of Technical Debt” (https://www.eecs.tufts.edu/~dsculley/papers/technical-debt.pdf). Technical debt is essentially the cost of developing software quickly, leaving behind things that must be cleaned up as you go. This paper contains a well thought-out list of ways in which Machine Learning (aka Artificial Intelligence) can incur more technical debt than non-ML development.

Tim O’Reilly
- •Tim wanted to reassure us that the hype suggesting AI and related technologies and products would put most of the existing workforce out of a job was probably false.
- His overarching premise was that the human race is not likely to run out of hard problems to solve anytime soon.
- However, of course the surge in AI technologies and products means both that the workforce will have to adapt, and that “business will have to change its rules” (published on LinkedIn: https://www.linkedin.com/pulse/survive-game-business-needs-update-rules-tim-o-reilly).
- In closing he paraphrased a Rilke poem to encourage us to “do things previously impossible”.
Tom Davenport, author, (“Competing on Analytics” and 15 other books)
- Tom was the first speaker I saw to outline a future where humans would work side by side with AI – though he pointed out that this is highly analogous to moments in the past where new technologies were introduced.
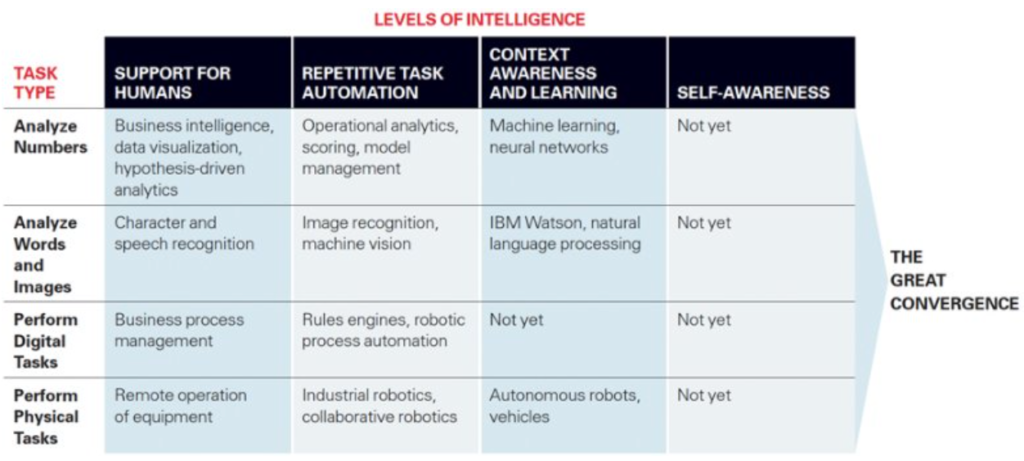
He considers four levels of Intelligence…
- Human support
- Repetitive task automation
- Context awareness and learning
- Self-aware intelligence
- …and shows how four types of tasks map to those four levels of intelligence. You can see AI is not yet at the self-awareness level.
Hilary Mason, Fast Forward
- Hilary has been a personal hero(one) of mine ever since I started to follow her in about 2009 after the term “data science” was coined. She contributed to the discussion around that term, and is trying again now to help define what an AI product is.
- One interesting aspect of her definition of an AI product is it has a feedback loop, unlike other kinds of products.
- Organizations may have data, or domain expertise, or ability to create an AI product, but usually not all three at once, especially startups.
- There’s a new development paradigm for AI products: the process is more experimental and has a new user experience.
Binh Han, Arimo
- Binh discussed how to shorten the time to effectiveness and lower the amount of training data that’s required to achieve a given level. of performance using human-in-the-loop “Deeply Active Learning”.
- It turns out that adding humans reduces the need for big data; instead, model training can be done with smaller data sets plus human curation and feedback to the algorithm.
Vikash Mansinghka, MIT Probabilistic Computing Project
- They’re working on using probabilistic programming techniques to push medical science further, as well as other complex, ambiguous areas of human knowledge where data is sparse and there are no rules.
- One product, BayesDB, found a new biomarker for Diabetes in 30 minutes, confirmed by medical researchers.
Yann Le Cun, Facebook
- Facebook users upload between 1B and 1.5B images every day. Each image is sent through two algorithms (CNN) within two seconds.
- Working on Memory-Augmented Neural Networks to optimize CNNs.
- Yann believes unsupervised learning (e.g., training an image recognition algorithm without having to provide “labels” like cat, dog, beach) is the future of AI, probably mostly because of his research interests and current employer.
Gary Marcus
- Maybe my favorite speaker, not that I didn’t like the others; but he was a kind of refreshing splash of cold water on the overheated general feeling that “the sky’s the limit” pervasive at the conference.
- His background is in neuroscience, which is probably what makes him assert that neuroscience is much more complex than current AI, and thus makes him somewhat dismissive of current AI progress.
- He spoke very quickly, yet clearly and engagingly. His main point was that current AI is narrowly defined, and not that good at anything other than the most common cases. It performs poorly or not at all on the “long tail” of cases
- One could summarize his main point by referencing an article in WIRED called “The best AI today flunks 8th grade science” (https://www.wired.com/2016/02/the-best-ai-still-flunks-8th-grade-science/).
Rana El Kaliouby, Affectiva
- Affectiva is building the largest repository of emotional data via facial recognition – they’ve scanned almost 5 million faces from various ethnicities around the world.
- Developers can download and use Affectiva’s SDK – they’re trying to push this out to the world to embed in AI products to make them more emotionally “aware”.
Francisco Webber, cortical
- Cortical is Working on deep NLP (Natural Language Processing), trying to move beyond simple word parsing into actual knowledge representation.
- The demo slides showed thoughtful visual representations of words and phrases, much deeper than just single-word processing; one could see two different analogous concepts displayed visually and “see” immediately that there was an analogy – not true of dissimilar concepts.
Ash Damle, Lumiata
- Lumiata seems to really be pushing the boundaries of healthcare analytics towards actual “precision medicine” able to suggest outcomes and treatments for individuals rather than subgroups.
- One of their key insights is that especially in healthcare, a data analyst has to understand all of the nuances of healthcare data, which is staggeringly complex and copious in the aggregate.
- They’re developing the “Lumiata Medical Graph” that combines health data from myriad sources with medical knowledge, and analyzes the relationships between them, allowing for the delivery of “hyper-personalized” insights across the entire healthcare network.
Some Favorite Quotes
Tom Davenport: “We’d probably rather be killed by a human driver than a machine”.
Aparna Chennapragada, Google (former lead of the Google Now project): “There’s a lot of irrational exuberance here … there’s a fine line between magical and flaky”.
Naveen Rao, who followed Gary Marcus’s “reality check” talk: “Don’t let Gary Marcus scare you”.
The Future
My take on the likely near-term future of AI is that it will:
- chip away at various problems, especially in automating selected parts of the well-defined ones
- enable truly new features and products, like Lumiata’s
- entirely take over some kinds of things currently being done by humans, especially the mind-numbing parts of some “knowledge work”
Predictions of when “the singularity” (the convergence of human and artificial intelligence – i.e., machines will be as smart as, or smarter than, humans) will happen range broadly, but something like 2040-2060 seems to be a consensus of the speakers here. Of course, this is kind of an intellectually lazy guess that translates to “I don’t really know, but probably not in 5-10 years, and less than a half century”. Predictions longer than, say, 20 years probably contain confidence levels so low as to be worthless.
I’m looking forward to seeing how the conference changes in 2017. Will the “irrational exuberance” have proven to be rational after all? What new products powered by AI will exist in a year’s time? What companies will emerge that are focusing on the middle ground of AI for augmentation and optimization of existing processes? Stay tuned…



